DeepReDuce: ReLU Reduction for Fast Private Inference
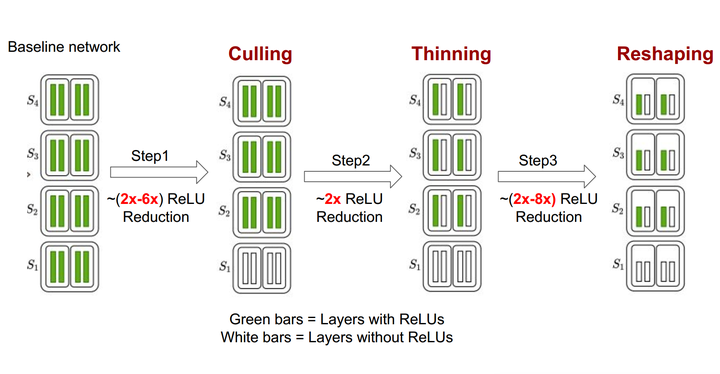 ReLU optimization steps in DeepReDuce
ReLU optimization steps in DeepReDuceAbstract
The recent rise of privacy concerns has led researchers to devise methods for private neural inference—where inferences are made directly on encrypted data, never seeing inputs. The primary challenge facing private inference is that computing on encrypted data levies an impractically-high latency penalty, stemming mostly from non-linear operators like ReLU. Enabling practical and private inference requires new optimization methods that minimize network ReLU counts while preserving accuracy. This paper proposes DeepReDuce - a set of optimizations for the judicious removal of ReLUs to reduce private inference latency. The key insight is that not all ReLUs contribute equally to accuracy. We leverage this insight to drop, or remove, ReLUs from classic networks to significantly reduce inference latency and maintain high accuracy. Given a network architecture, DeepReDuce outputs a Pareto frontierof networks that tradeoff the number of ReLUs and accuracy. Compared to the state-of-the-art for private inference DeepReDuce improves accuracy and reduces ReLU count by up to 3.5% (iso-ReLU count) and 3.5×(iso-accuracy), respectively.
Nandan Kumar Jha
Ph.D., New York University · Representation Learning, Scaling Laws, and High-Dimensional Learning Dynamics
I study nonlinear representation dynamics in large language models, focusing on how nonlinearities, architecture, and optimization jointly shape representational geometry, scaling behavior, and usable computational capacity.