ULSAM: Ultra-lightweight subspace attention module for compact convolutional neural networks
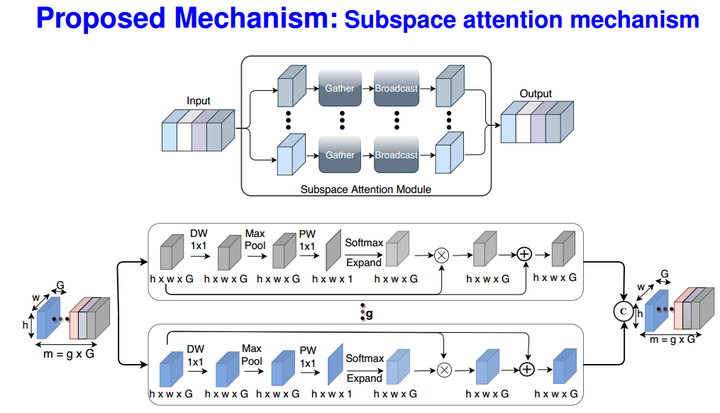 ULSAM module design
ULSAM module designAbstract
The capability of the self-attention mechanism to model the long-range dependencies has catapulted its deployment in vision models. Unlike convolution operators, self-attention offers infinite receptive field and enables compute- efficient modeling of global dependencies. However, the existing state-of-the-art attention mechanisms incur high compute and/or parameter overheads, and hence unfit for compact convolutional neural networks (CNNs). In this work, we propose a simple yet effective “Ultra-Lightweight Subspace Attention Mechanism” (ULSAM), which infers different attention maps for each feature map subspace. We argue that leaning separate attention maps for each feature subspace enables multi-scale and multi-frequency feature representation, which is more desirable for fine-grained image classification. Our method of subspace attention is orthogonal and complementary to the existing state-of-the- arts attention mechanisms used in vision models. ULSAM is end-to-end trainable and can be deployed as a plug-and- play module in the pre-existing compact CNNs. Notably, our work is the first attempt that uses a subspace attention mechanism to increase the efficiency of compact CNNs. To show the efficacy of ULSAM, we perform experiments with MobileNet-V1 and MobileNet-V2 as backbone architectures on ImageNet-1K and three fine-grained image classification datasets. We achieve ≈13% and ≈25% reduction in both the FLOPs and parameter counts of MobileNet-V2 with a 0.27% and more than 1% improvement in top-1 accuracy on the ImageNet-1K and fine-grained image classification datasets (respectively).
Nandan Kumar Jha
Ph.D., Electrical and Computer Engineering
I study nonlinear representation dynamics in large language models, focusing on how nonlinearities, architecture, and optimization jointly shape representational geometry, scaling behavior, and usable computational capacity.