Entropy-Guided Attention for Private LLMs
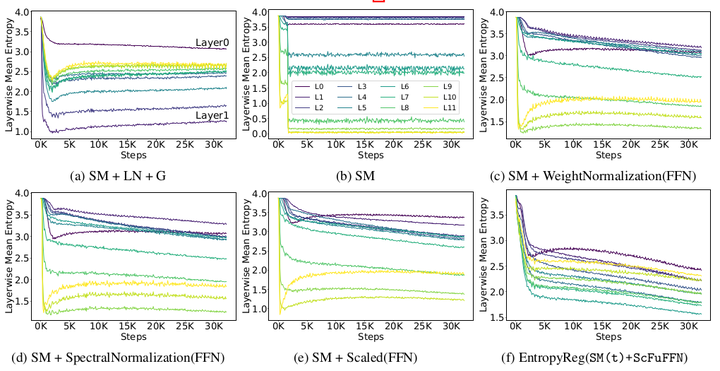 Layerwise entropy dynamics in GPT-2 models with fewer nonlineairty
Layerwise entropy dynamics in GPT-2 models with fewer nonlineairtyAbstract
We introduce an information-theoretic framework to characterize the role of nonlinearities in decoder-only language models, laying a principled foundation for optimizing transformer-architectures tailored to the demands of Private Inference (PI). By leveraging Shannon’s entropy as a quantitative measure, we uncover the previously unexplored dual significance of nonlinearities, beyond ensuring training stability, they are crucial for maintaining attention head diversity. Specifically, we find that their removal triggers two critical failure modes, entropy collapse in deeper layers that destabilizes training, and entropic overload in earlier layers that leads to under-utilization of Multi-Head Attention’s (MHA) representational capacity. We propose an entropy-guided attention mechanism paired with a novel entropy regularization technique to mitigate entropic overload. Additionally, we explore inference-efficient alternatives to layer normalization for preventing entropy collapse and stabilizing the training of LLMs with reduced-nonlinearities. Our study bridges the gap between information theory and architectural design, establishing entropy dynamics as a principled guide for developing efficient PI architecture.
Nandan Kumar Jha
Ph.D., Electrical and Computer Engineering
I study nonlinear representation dynamics in large language models, focusing on how nonlinearities, architecture, and optimization jointly shape representational geometry, scaling behavior, and usable computational capacity.