Nandan Kumar Jha
Nandan Kumar Jha
Home
Research
Publications
Highlights
Talks
Media
Contact
1
NerVE: Nonlinear Eigenspectrum Dynamics in LLM Feed-Forward Networks
Introduces eigenspectrum-based tools for tracking how nonlinearities reshape FFN representation geometry across layers and model scales.
Nandan Kumar Jha
,
Brandon Reagen
PDF
Cite
Code
Project
Circa: Stochastic ReLUs for Private Deep Learning
Circa reduces the runtime overhead of ReLU operation by 1.9x by decoupling the sign evaluation and multiplication steps in the Garbled circuit with no loss in accuracy. Further, it achieves a total of 4.7x runtime reduction by employing the sign approximation in the Garbled circuit by leveraging the error-tolerant properties of neural networks within a 1% accuracy margin.
Zahra Ghodsi
,
Nandan Kumar Jha
,
Brandon Reagen
,
Siddharth Garg
PDF
Cite
Poster
Spectral Scaling Laws in Language Models: How Effectively Do Feed-Forward Networks Use Their Latent Space?
Studies how effectively LLM feed-forward networks use latent width through soft- and hard-spectral-rank scaling laws.
Nandan Kumar Jha
,
Brandon Reagen
PDF
Cite
ICML 2025 AIW
Related code
DeepReDuce: ReLU Reduction for Fast Private Inference
DeepReDuce is a set of optimizations for the judicious removal of ReLUs to reduce private inference latency by leveraging the ReLUs heterogeneity in classical networks. DeepReDuce strategically drops ReLUs upto 4.9x (on CIFAR-100) and 5.7x (on TinyImageNet) for ResNet18 with no loss in accuracy. Compared to the state-of-the-art for private inference DeepReDuce improves accuracy and reduces ReLU count by up to 3.5% (iso-ReLU) and 3.5×(iso-accuracy), respectively.
Nandan Kumar Jha
,
Zahra Ghodsi
,
Siddharth Garg
,
Brandon Reagen
PDF
Cite
Poster
Slides
ICML video
Long video
Spotlight slides
Press release
DRACO: Co-Optimizing Hardware Utilization and Performance of DNNs on Systolic Accelerator
Co-optimizes DNN structure for systolic accelerators, improving hardware utilization, inference latency, and energy efficiency without requiring hardware dataflow changes.
Nandan Kumar Jha
,
Shreyas Ravishankar
,
Sparsh Mittal
,
Arvind Kaushik
,
Dipan Mandal
,
Mahesh Chandra
PDF
Cite
Slides
Video
DOI
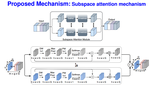
ULSAM: Ultra-lightweight subspace attention module for compact convolutional neural networks
Introduces an ultra-lightweight subspace-attention module for compact CNNs, reducing parameters and FLOPs while improving accuracy on ImageNet and fine-grained recognition benchmarks.
Rajat Saini
,
Nandan Kumar Jha
,
Bedanta Das
,
Sparsh Mittal
,
C Krishna Mohan
PDF
Cite
Code
Poster
Slides
Video
DOI
E2GC: Energy-efficient group convolution in deep neural networks
The number of groups (g) in group convolution (GConv) is selected to boost the predictive performance of deep neural networks (DNNs) in …
Nandan Kumar Jha
,
Rajat Saini
,
Subhrajit Nag
,
Sparsh Mittal
PDF
Cite
Slides
DOI
The Ramifications of Making Deep Neural Networks Compact
The recent trend in deep neural networks (DNNs) research is to make the networks more compact. The motivation behind designing compact …
Nandan Kumar Jha
,
Sparsh Mittal
,
Govardhan Mattela
PDF
Cite
Slides
DOI
Characterizing and Optimizing End-to-End Systems for Private Inference
Studies private inference as an end-to-end systems problem, identifying bottlenecks across the full stack and optimizing performance beyond isolated model changes.
Karthik Garimella
,
Zahra Ghodsi
,
Nandan Kumar Jha
,
Siddharth Garg
,
Brandon Reagen
PDF
Cite
Code
Poster
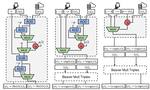
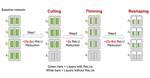
DeepReShape: Redesigning Neural Networks for Efficient Private Inference
DeepReShape is the first work to conduct a rigorous characterization of desirable neural network attributes for efficient Private Inference (PI). We discovered that distinct network attributes are required for different ReLU counts; in particular, wider networks are beneficial only for higher ReLU counts, whereas networks with a greater proportion of least-critical ReLU are desirable for lower ReLU counts. Further, we introduced a novel network design principle called “ReLU-equalization” to strategically allocate channels within the network to optimize ReLUs and FLOPs efficiency simultaneously. DeepReShape outperforms the current SOTA (SENets, ICLR'23) by achieving a 2.1% increase in accuracy and a 5.2x faster runtime at iso-ReLU counts on CIFAR-100, and an 8.7x faster runtime at iso-accuracy on the TinyImageNet dataset.
Nandan Kumar Jha
,
Brandon Reagen
PDF
Cite
Slides
Video
Cite
×